Automating Work Allocation — Part 2
Workload Balancing
We begin here where we left off in Part 1 (Of course!)
To recap, we did some predictions, based on a model with reasonably good evaluation scores.
Let’s see what it produced:

See the distribution?
If I was a Vamshi, I would curse my own self for overloading me (sounds so recursive). On the other hand, I, as Brad, would be the poster boy of work-life balance (with scales tilted in favor of Life).
Upon closer inspection, the model seems to be penalizing long time resources by showing more affinity to them and assigning them more items. At the same time underloading the newer resources.
For any PM, this would be an opportunity for a bit of Resource Smoothing (unless you intentionally choose to overload some, to have others available for adhoc tasks). The feeling of being equitable in work distribution to the team, would be an added bonus.
We could choose to balance the workload manually, by going to the UI and rejigging the items, pondering over what to assign to whom, reinventing the whole wheel.
Or, we could automate this, with the help of, what else, but, Machine Learning !
Probability Estimates
model.predict_proba
The returned estimates for all classes are ordered by the label of classes. (scikit-learn.org)
probability = model.predict_proba(features_pred)
print(probability)
[[ 0.03157049 0.10609123 0.03379352 ..., 0.02531732 0.0187342
0.07398942]
[ 0.03546799 0.12019077 0.04076321 ..., 0.03060364 0.02157475
0.08596545]
[ 0.0305953 0.14906867 0.03259022 ..., 0.02917956 0.01847843
0.21378922]
...,
[ 0.02694778 0.04595638 0.03569155 ..., 0.01942517 0.01370765
0.09251289]
[ 0.02751238 0.15087763 0.06788408 ..., 0.04300025 0.02239455
0.08754095]
[ 0.0217629 0.03658622 0.02401338 ..., 0.01502456 0.01107735
0.06867179]]For the uninitiated, predict_proba returns an array of probabilities of each class (in our case, developer/resource), corresponding to each input (in our case, Work Item/JIRA Key). So, imagine the above as a table with columns as Developer names and Rows as JIRA/Work item
Juxtaposition
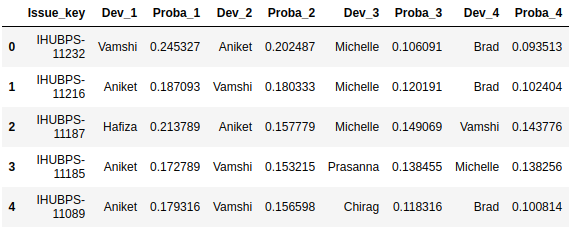
In it’s current form, the proba matrix may not be of much use . But if we were able to add Dev Id and then order the Dev IDs in the reverse order of probabilities, per JIRA/Work item , we would get an ordered list of Developers per JIRA/Work item.
E.g.
Convert the first line of the array, from:
[ 0.03157049 0.10609123 0.03379352 ..., 0.02531732 0.0187342
0.07398942]To:
[(3, 0.24532665837341894), (5, 0.20248744000028043), (1, 0.10609122679040479), (8, 0.093513200785268383), (7, 0.082245774513282244), (11, 0.073989416771466435), (4, 0.05387975511436302), (2, 0.033793515531694802), (6, 0.033050994049388341), (0, 0.031570490972031739), (9, 0.02531732352188306), (10, 0.018734203576517859)]
Dev 3 Probability is 0.245326658373
Dev 5 Probability is 0.20248744
Dev 1 Probability is 0.10609122679
Dev 8 Probability is 0.0935132007853
Dev 7 Probability is 0.0822457745133
Dev 11 Probability is 0.0739894167715
Dev 4 Probability is 0.0538797551144
Dev 2 Probability is 0.0337935155317
Dev 6 Probability is 0.0330509940494
Dev 0 Probability is 0.031570490972
Dev 9 Probability is 0.0253173235219
Dev 10 Probability is 0.0187342035765
Using (sample code)
class_proba=(sorted( zip( model.classes_, probability[0] ), key=lambda x:x[1], reverse=True)[:n_best])
#print(np.array(sorted( zip( model.classes_, probability[0] ), key=lambda x:x[1], reverse=True)[:1]))
print(type(class_proba))
np.size(class_proba,axis=0)
for dev,proba in class_proba:
print(“Dev” , dev , “Probability is” , proba)
We now have a Dataframe with not only the best predicted developer/resource under Dev_1 column (which is what the ‘model.predict’ function returns when called upon), but also a listing of the next best resource and next best and so on.
Find — Replace
Now, all we need to do is ‘Find the overloaded resources’ items exceeding their fair capacity’ and ‘Replace these overloaded items’ assigned resource with an underloaded resource’ (at the same time making sure not to overload our previously underloaded resources).
Easier said than done. Let’s enumerate the steps, along with the dirty details.
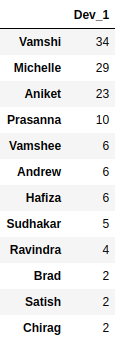
1 —Analyze the data
all_counts=pd.DataFrame(jira_dev_seq_df[‘Dev_1’].value_counts())
all_counts
2 — Identify JIRAs/Work items belonging to Overloaded Resources
total_jira_issues=jira_dev_seq_df.Issue_key.count()
total_developers=jira_dev_seq_df.Dev_1.nunique()
avg_jiras_per_dev=(total_jira_issues/total_developers).round()
overloaded_jira_dev=jira_dev_seq_df.loc[jira_dev_seq_df[‘jira_seq’] > avg_jiras_per_dev]
overloaded_jira_dev.Dev_1.value_counts()
Vamshi 23
Michelle 18
Aniket 12
Name: Dev_1, dtype: int64These are the items over the ideal allocation of overloaded resources and should be redistributed to underloaded resources
3 — Replace overloaded with underloaded resources
Using the shift operator, replace the overloaded first choice with the next choice of non-overloaded resource
jira_dev_df.iloc[row_index_to_shift,1:-1] = jira_dev_df.iloc[row_index_to_shift,1:-1].shift(periods=-1,axis=1)
jira_dev_df[‘jira_seq’] = jira_dev_df.groupby(‘Dev_1’)[‘Proba_1’].rank(method=”first”, ascending=False)
print(‘Replacing ‘, Dev1, ‘with ‘, Dev2 , ‘for JIRA ‘,jira_item[1] )
Replacing Aniket with Andrew for JIRA IHUBPS-11037
Replacing Aniket with Andrew for JIRA IHUBPS-10806
Replacing Aniket with Andrew for JIRA IHUBPS-10804
Replacing Aniket with Andrew for JIRA IHUBPS-10803
Replacing Aniket with Andrew for JIRA IHUBPS-10560
Replacing Aniket with Andrew for JIRA IHUBPS-10416
Replacing Michelle with Satish for JIRA IHUBPS-10647
Replacing Michelle with Satish for JIRA IHUBPS-10583
Replacing Michelle with Ravindra for JIRA IHUBPS-10862
Replacing Michelle with Ravindra for JIRA IHUBPS-10849
Replacing Michelle with Ravindra for JIRA IHUBPS-10602
Replacing Michelle with Ravindra for JIRA IHUBPS-10594
Replacing Michelle with Ravindra for JIRA IHUBPS-10527
Replacing Michelle with Ravindra for JIRA IHUBPS-10507
Replacing Michelle with Ravindra for JIRA IHUBPS-9321
Replacing Michelle with Hafiza for JIRA IHUBPS-10543
Replacing Michelle with Hafiza for JIRA IHUBPS-10395
Replacing Michelle with Hafiza for JIRA IHUBPS-10511
Replacing Vamshi with Ravindra for JIRA IHUBPS-10535
Replacing Vamshi with Vamshee for JIRA IHUBPS-10873
Reassigned 20
....
....
....
....
Reassigned 11
Replacing Prasanna with Brad for JIRA IHUBPS-11185
Replacing Ravindra with Aniket for JIRA IHUBPS-10768
Replacing Hafiza with Chirag for JIRA IHUBPS-10756
Replacing Michelle with Chirag for JIRA IHUBPS-10544
Replacing Michelle with Chirag for JIRA IHUBPS-10542
Replacing Michelle with Chirag for JIRA IHUBPS-10392
Replacing Vamshi with Michelle for JIRA IHUBPS-10860
Replacing Vamshi with Hafiza for JIRA IHUBPS-10195
Reassigned 8
....
....
Replacing Sudhakar with Chirag for JIRA IHUBPS-7939
Replacing Chirag with Brad for JIRA IHUBPS-10860
Replacing Brad with Andrew for JIRA IHUBPS-10908
Replacing Vamshi with Satish for JIRA IHUBPS-5540
Reassigned 4
Replacing Andrew with Sudhakar for JIRA IHUBPS-10806
Replacing Aniket with Vamshee for JIRA IHUBPS-10511
Replacing Sudhakar with Satish for JIRA IHUBPS-10243
Reassigned 3
Reassigned 0
Reassigned 0
Reassigned 0
Reassigned 0
Reassigned 0
jira_count= 53
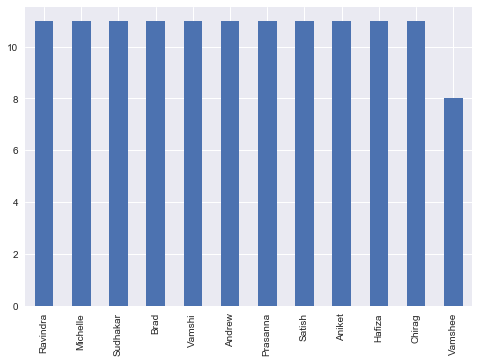
total_reassignment_count= 82And just like that……
The entire Work queue is smoothened out
Conclusion
In this post we have seen how to smoothen out the Work Allocation, if it is uneven or unbalanced as determined in the first round of predictions.
GIT Notebook Link
